背景
主要监控数据来源
1.阿里云工作台的监控 2.kibana内部的Monitoring
第一次升级
我们从 2核8g 2节点,升级到 2核8g 3节点,性能一点没变。 老配置运行了2年以上的时间,基本没有问题。
这次升级,就是因为2节点存在脑裂问题。
这里有2点需要关心:
Q1. 为什么可以2节点可以运行2年多,很少出问题?
// TODO
附录1: minimum_master_nodes设定对你的集群的稳定极其重要。设置成1可以保证集群的功能,但是就无法防止集群脑裂了
GET /_cluster/settings
响应如下:
{
"persistent" : {
"cluster" : {
"routing" : {
"allocation" : {
"node_concurrent_incoming_recoveries" : "1",
"node_concurrent_recoveries" : "1",
"exclude" : {
"_ip" : ""
},
"enable" : "all"
}
}
},
"search" : {
"isolator" : {
"enabled" : "true"
},
"max_buckets" : "10000"
},
"monitoring" : {
"collector" : {
"kmonitor" : {
"enabled" : "true"
}
}
},
"discovery" : {
"zen" : {
"minimum_master_nodes" : "2" // 这里的配置
}
}
},
"transient" : {
"cluster" : {
"routing" : {
"allocation" : {
"node_concurrent_incoming_recoveries" : "1",
"cluster_concurrent_rebalance" : "6",
"node_concurrent_recoveries" : "1",
"exclude" : {
"_ip" : ""
}
}
}
},
"indices" : {
"recovery" : {
"max_bytes_per_sec" : "50mb"
}
}
}
}
Q2. 2节点时出问题怎么办的? // TODO
Q3. 为什么又要升级为3节点了? 1.试图加节点来提升性能,升级后基本性能没有提升。// 核心需求 2.防止脑裂。这个不是刚性需求。
第二次升级
过了半年,再次升级 为 4核8g 三节点。 搜索耗时,从30ms减为15ms。
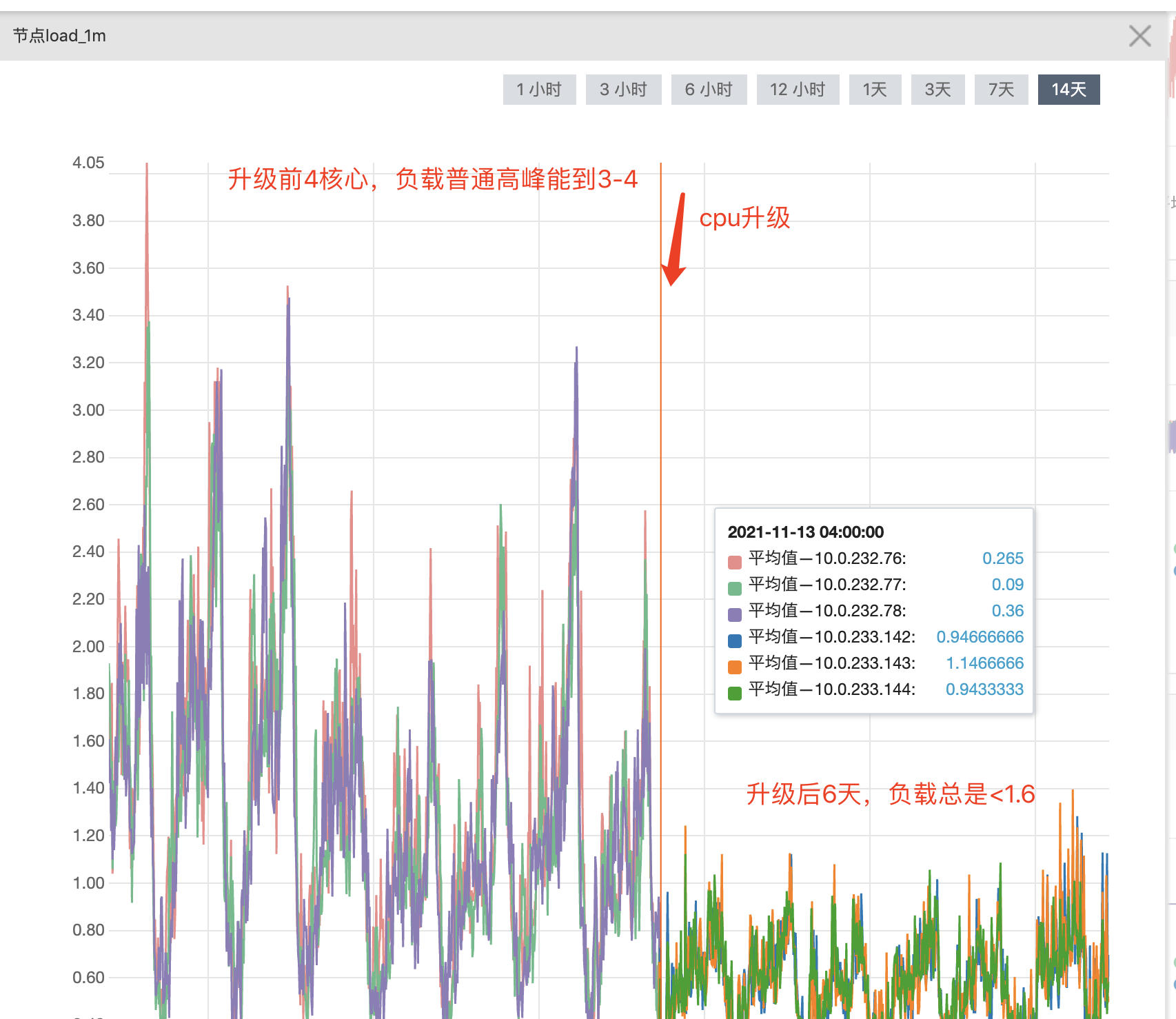
升级原因: 注意是看的es节点的负载。 4核机器,负载能达到3-4左右,所以负载较高
升级前情况:
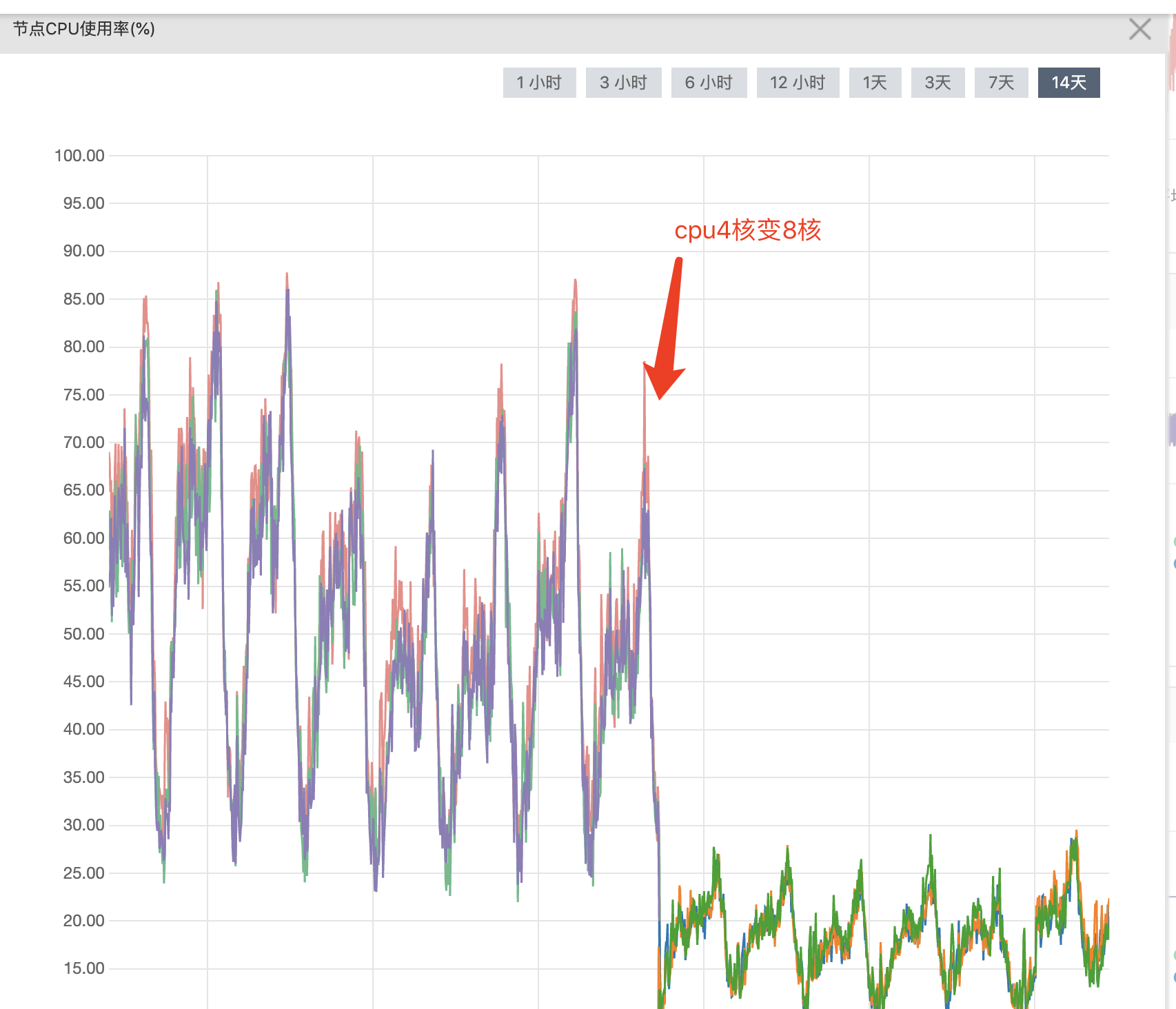
- cpu使用率: 高峰能达到80-90%。明显吃紧。
- 负载: 4核,负载高峰能到3-4。明显吃紧。 // 负载=4表示资源100%用完
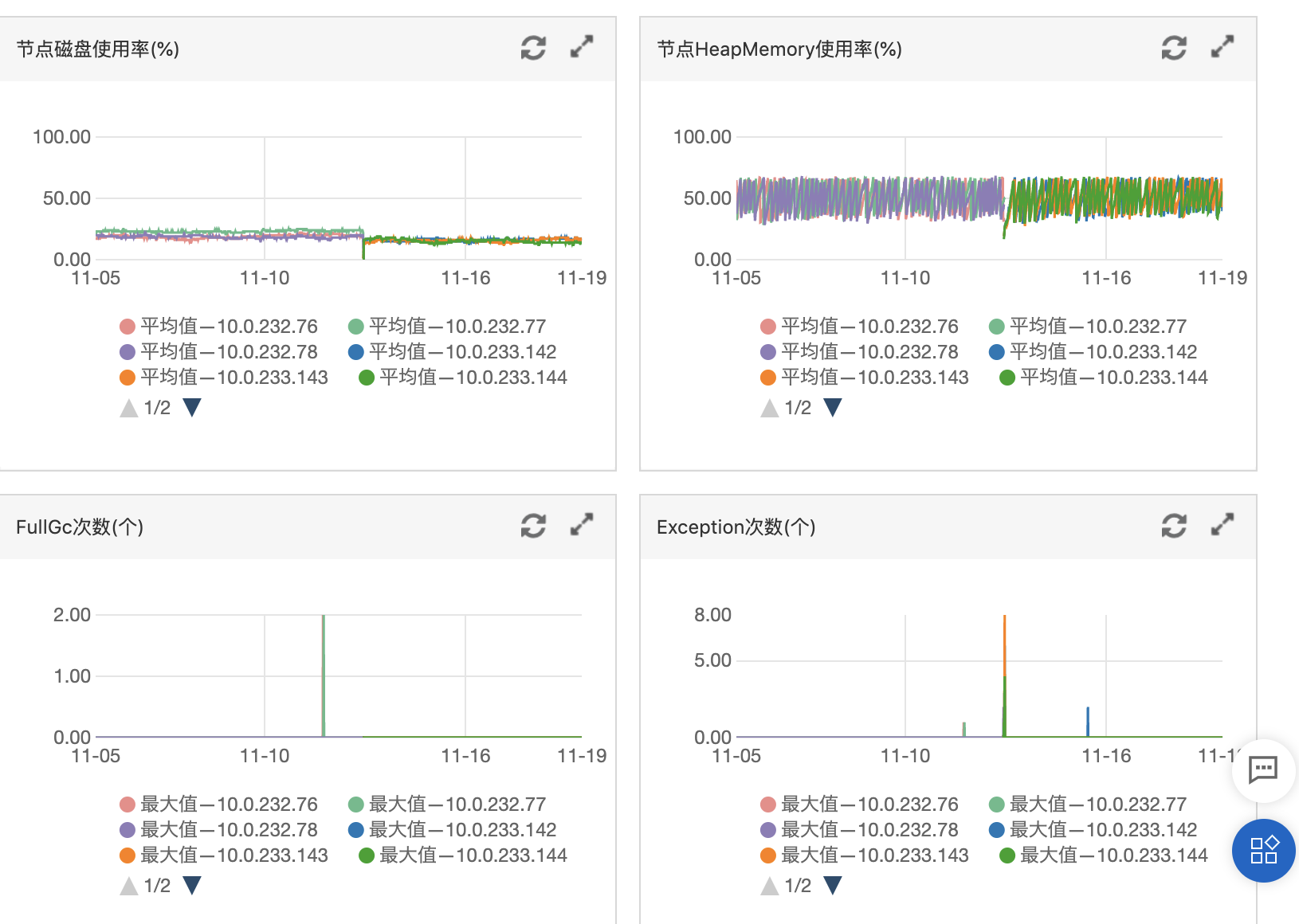
- 内存: FullGc基本没有,说明内存不吃紧。 同时还有heapMemery使用率
- 磁盘: 磁盘使用率很低<30%,不吃紧。
kibana内部的Monitoring监控数据
从kibana可以看到es节点的监控,升级后监控(cpu使用率和负载)如图:
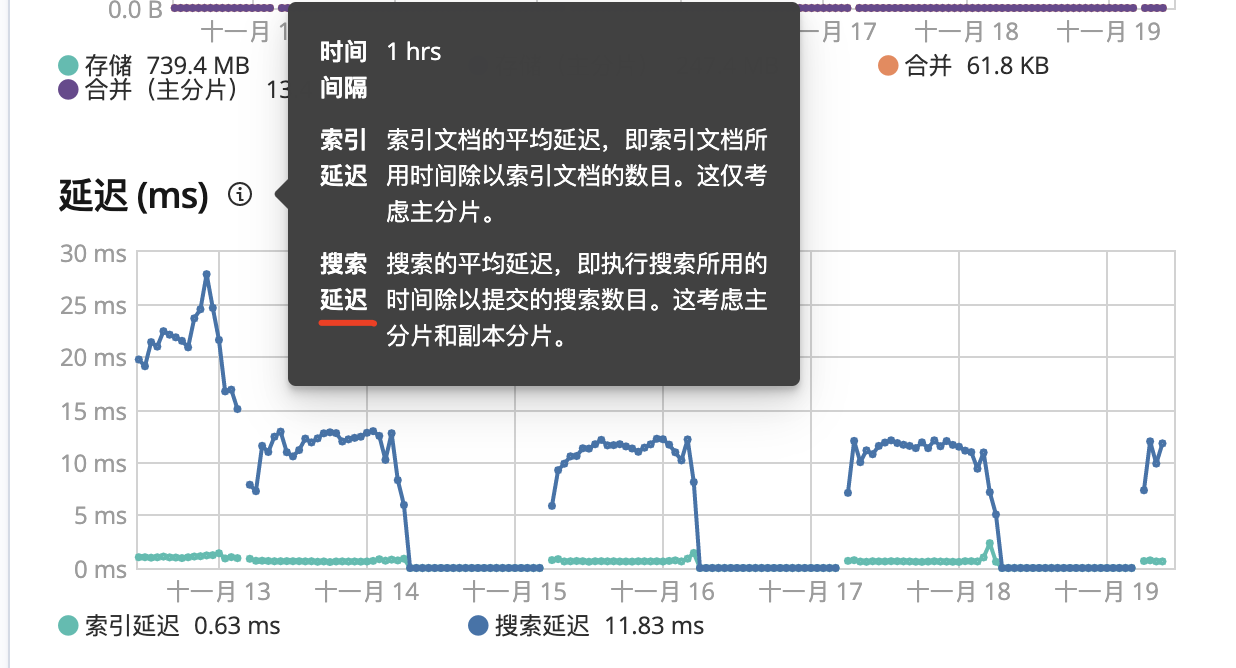
es机器配置升级后搜索延迟为10-15ms,升级前是30-40ms(升级的忘记截图了)
阿里云工作台监控数据
es机器配置升级前后-节点负载对比
es机器配置升级前后-cpu使用率对比
内存和磁盘都够用
第三次升级 TODO
2022年10月,升级cpu,4核8g三节点 -> 8核8g三节点
参考
1.Elasticsearch: 权威指南 » 管理、监控和部署 » 部署 » 重要配置的修改-最小主节点数
原创文章转载请注明出处: es配置升级的经历